In NLP, embedding is a key conpoent for many downstream tasks such as classification, NLI etc. A good loss function usually benefits for embedding of training. Recently, I have read two papers related to pair-wise loss. The opinions of the two papers inpired me that loss function should have flexiblity to samples. Giving more penalities on hard sample is benefical to training.
The role of temperature
The first paper focus on the hyperparameter temperature of infoNCE. It shows that the temperature playing a role controlling the strength of penalties on hard negative samples.
The formula of infoNCE can be expressed as:
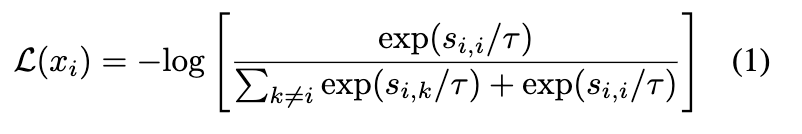 The gradient of positive and negative samples are:
The gradient of positive and negative samples are:
 In the formula, gradients with respect to negative samples is proportional to the exponential term, indicating that the contrastive loss is a hardness-aware loss function.
When decreasing temperature, hard negative sample will get more penality than easy negative.
In the formula, gradients with respect to negative samples is proportional to the exponential term, indicating that the contrastive loss is a hardness-aware loss function.
When decreasing temperature, hard negative sample will get more penality than easy negative.

Circle loss
Actually, infoNCE is a cross entropy loss, while circle loss is not.
Circle loss is as following:
 Its motivation comes from ambiguous convergence status[2]. The idea of circle loss is quite clear, just adding weighting factor a_s and a_n for both s_p and s_n corresponding to positive and negative samples.
Its motivation comes from ambiguous convergence status[2]. The idea of circle loss is quite clear, just adding weighting factor a_s and a_n for both s_p and s_n corresponding to positive and negative samples.
references
- [1] Understanding the Behaviour of Contrastive Loss–2021
- [2] Circle Loss: A Unified Perspective of Pair Similarity Optimization–2020