Entity matching, also known as record linkage, is a crucial aspect of Natural Language Processing (NLP) that involves identifying and connecting data to determine whether two entities refer to the same real-world object or not.[1]
Problem definition
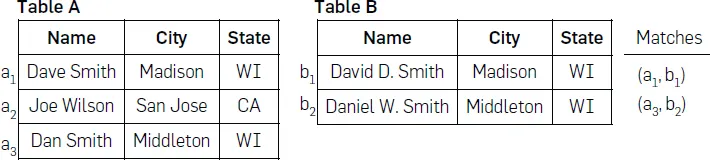
Let $𝐴$ and $𝐵$ be two data sources. 𝐴 has the attributes $(𝐴_1, 𝐴_2, …, 𝐴_𝑛)$, and we denote records as $𝑎 = (𝑎_1, 𝑎_2, …, 𝑎_𝑛) ∈ 𝐴$. Similarly, $𝐵$ has the attributes $(𝐵_1, 𝐵_2, …, 𝐵_𝑚)$, and we denote records as $𝑏 = (𝑏_1, 𝑏_2, …, 𝑏_𝑚) ∈ 𝐵$. $A$ data source is a set of records, and a record is a tuple following a specific schema of attributes. An attribute is defined by the intended semantics of its values. So $𝐴_𝑖 = 𝐵_𝑗$ if and only if values $𝑎_𝑖$ of $𝐴_𝑖$ are intended to carry the same information as values $𝑏_𝑗$ of $𝐵_𝑗$, and the specific syntactics of the attribute values are irrelevant. Attributes can also have metadata (like a name) associated with them, but this does not affect the equality between them. We call the tuple of attributes $(𝐴_1, 𝐴_2, …, 𝐴_𝑛)$ the schema of data source $𝐴$, and correspondingly for $𝐵$. The goal of entity matching is to find the largest possible binary relation $𝑀 ⊆ 𝐴 × 𝐵$ such that $𝑎$ and $𝑏$ refer to the same entity for all $(𝑎, 𝑏) ∈ 𝑀$.[2] Obviously, the number of candidate all potential pairs is Cartesian product $|𝐴 × 𝐵|$.
Traditional entity matching process
Tranditional entity matching process consists of data-processing, schema matching, blocking, record pair comparison and classification.
-
Schema matching is aimed to find out which attributes should be compared to one another, essentially identifying semantically related attributes. In practice, this step is often performed manually as part of the preprocessing step, simply making sure to transform both data sources into the same schema format.
-
Since the number of potential matches grows quadratically, it is common to pick out candidate pairs $𝐶 ⊆ 𝐴 × 𝐵$ in a separate step before any records are compared directly. This step is called as blocking, and its goal is to bring down the number of potential matches $ 𝐶 ≪ 𝐴 × 𝐵 $ to a level where record-to-record comparison is feasible. -
When the number of candidate pairs $ 𝐶 $ has been reduced to a manageable amount, we can compare individual records $(𝑎, 𝑏) ∈ 𝐶$. The pairwise comparison results in a similarity vector $𝑆$, consisting of one or more numerical values indicating how similar or dissimilar the two records are. - Lastly, the objective of the classification step is to classify each candidate pair as either match or nonmatch based on the similarity vector. In cases where |𝑆 | = 1, simple thresholding might be enough, while when |𝑆 | > 1, one needs more elaborate solutions. Frequently, the process of pairwise comparison and classification is combined into a single comparison step in modeling. In the overall process, the two key components are blocking and comparison.

Metrics
For blocking:
-
$PR = C / 𝐴 × 𝐵 $ -
$P/E = C / 𝐴 $
For comparsion:
- precision/recall measures
- $F_1$
Datasets
The early approaches to entity matching were mostly concerned with matching personal records(census data or medical records). Such datasets are usually not publicly available due to privacy concerns.[2]
An overview of the most popular public datasets has been listed below:
