As the wildspread of LLMs, prompting engineering has been mainstream. Prompting is cool and all, but isn’t it a waste of compute to encode a prompt over and over again? Moreover, some prompts are quite long, which will cost a lot of tokens for most openai api user. And in the document-QA scenario, firstly, the document is split into chunks, and retrieved by query. Then retrieved chunk and query spliced into prompt for ChatGPT. This process is quite inefficient, because chunk usually contains irrelative content. This will lower the accuary of answer. The above content inspired me to explore the possibility of compressing prompts effectively. This post introduces three method.
CompressGPT
Yasyf took@VictorTaelin’s awesome experiments around compressing GPT prompts and built CompressGPT. It is very easy to use in your langchain code by changing just one line[1]. Although the compression process will still comsume tokens, but it works for some long prompts will be used for many times. Because without compression, every time you use the prompt, you need to encode it again. The author claims it can lead to 70% token usage deduction![1]
Contextual Compression
ContextualCompressionRetriever, its core idea is simple: given a specific query, we should be able to return only the documents relevant to that query, and only the parts of those documents that are relevant.[2]
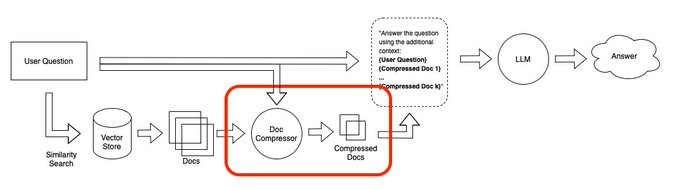 This componet is quite useful for improving the performance of QA. Because the irrelative content will harm the quality of ChatGPT.[3]
However, this method can’t save tokens, even may increase cost of tokens.
This componet is quite useful for improving the performance of QA. Because the irrelative content will harm the quality of ChatGPT.[3]
However, this method can’t save tokens, even may increase cost of tokens.
gist tokens
[5] proposed to compress prompts up to 26x by using “gist tokens”, saving memory+storage and speeding up LM inference.
 This idea is quite similar as Prefix Tuning, except [4] pretends template representing task ahead of tokens.
The drawback is that gist token can’t be applied for openai-api directly to save tokens.
This idea is quite similar as Prefix Tuning, except [4] pretends template representing task ahead of tokens.
The drawback is that gist token can’t be applied for openai-api directly to save tokens.