Recently, I found an interesting paper[2] from twitter[1]. Below are my notes.
Catastrophic Forgetting
The “pre-training and fine-tuning” paradigm is applied in may applications. However, the fine-tuning operation could lead to severe degeneration of LM’s general capabilities beyond the targeted domain. Such a phenomenon is commonly referred as catastrophic forgetting. It is also called “alignment tax” in the paper of InstructGPT[3]. This paper proposes a model merging method named LLM-Cocktail[2] which can mitigate the problem of catastrophic forgetting.
Cocktail Paradigm
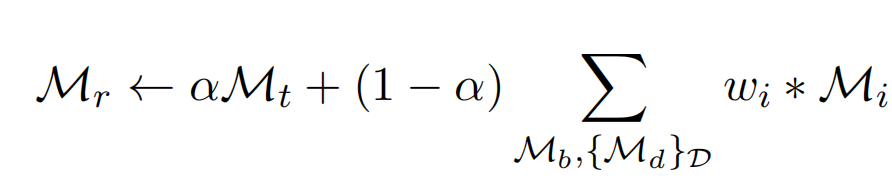

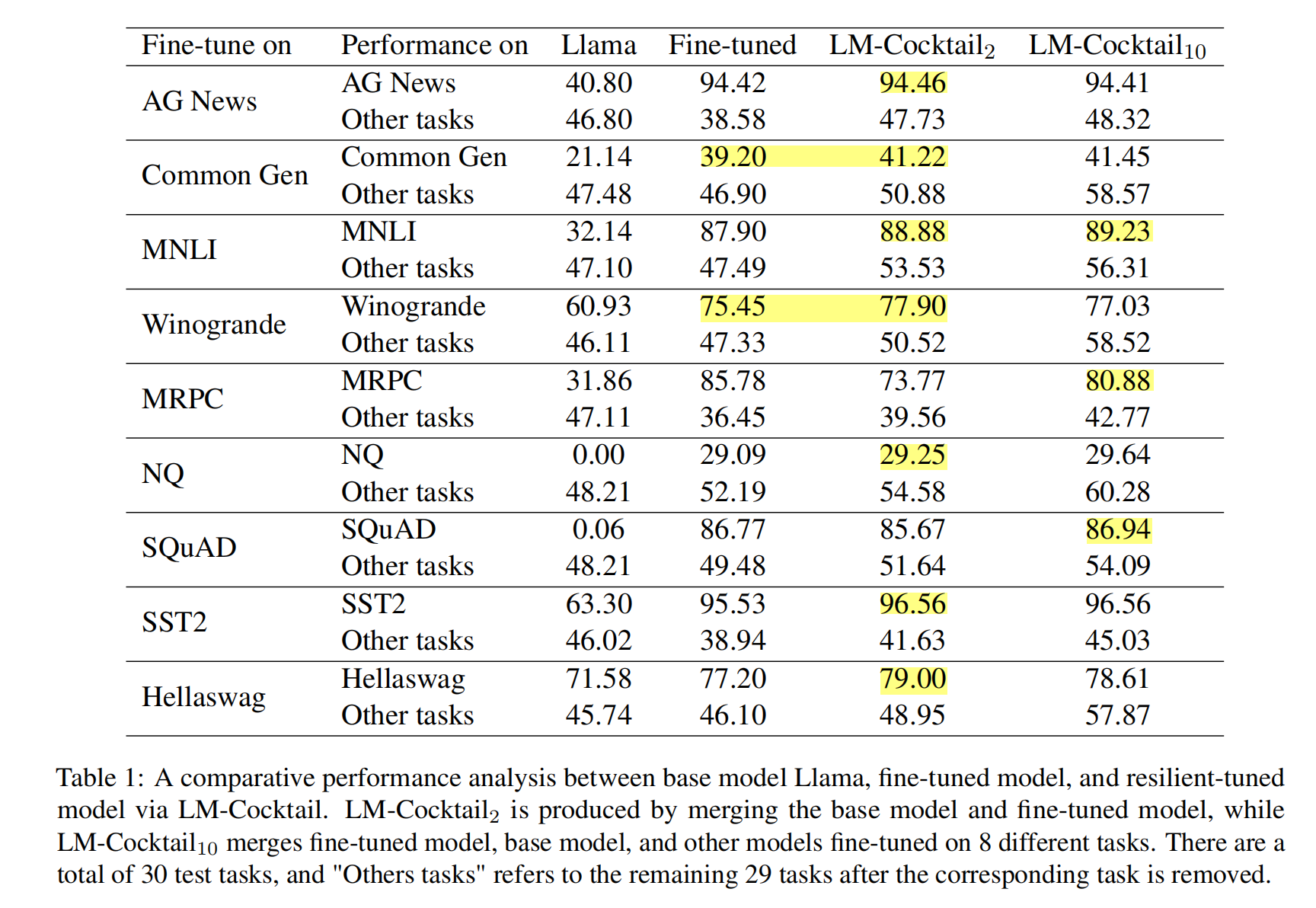
Performace
The resilient-tuned model via LLM-Cocktail outperforms both base model and fine-tuned model in 8 different fine-tuning target tasks. Meanwhile LLM-Cocktail(only merging the base model and fine-tuned model) achieves best in 7(not fine-tuning) other tasks.
Comment
From the view of ensembling, LLM-Cocktail is a weight-space model ensembling method. Conventional ensembling method usually combine the outputs of many models to improve the performance. The drawback is the cost of inference increases rapidly. Weight-space model ensembling method can avoid this drawback.