LLMs have been applied in many fields such as chatbot, information extraction[1] and so on.
Last week, some thoughts on ChatGPT have been posted. This post will list some works which apply LLMs as generator of corpus.
ChatAug
ChatAug[2] apply ChatGPT for data augmentation. As the framework show below, this work input samples into ChatGPT and prompt ChatGPT to generate samples that preserves semantic consistency with inputed sample.

Self-Instruct
Self-Instruct[3] is a semi-automated process for instruction-tuning a pretrained LM using instructional signals from the model itself.
 Its process starts with a small seed set of tasks (one instruction and one input-output instance for each task) as the task pool. Random tasks are sampled from the task pool, and used to prompt an off-the-shelf LM to generate both new instructions and corresponding instances, followed by filtering low-quality or similar generations, and then added back to the initial repository of tasks. The resulting data can be used for the instruction tuning of the language model itself later to follow instructions better.
Alpaca[4] model is trained on 52K instruction-following demonstrations generated in the style of self-instruct using text-davinci-003.
Its process starts with a small seed set of tasks (one instruction and one input-output instance for each task) as the task pool. Random tasks are sampled from the task pool, and used to prompt an off-the-shelf LM to generate both new instructions and corresponding instances, followed by filtering low-quality or similar generations, and then added back to the initial repository of tasks. The resulting data can be used for the instruction tuning of the language model itself later to follow instructions better.
Alpaca[4] model is trained on 52K instruction-following demonstrations generated in the style of self-instruct using text-davinci-003.
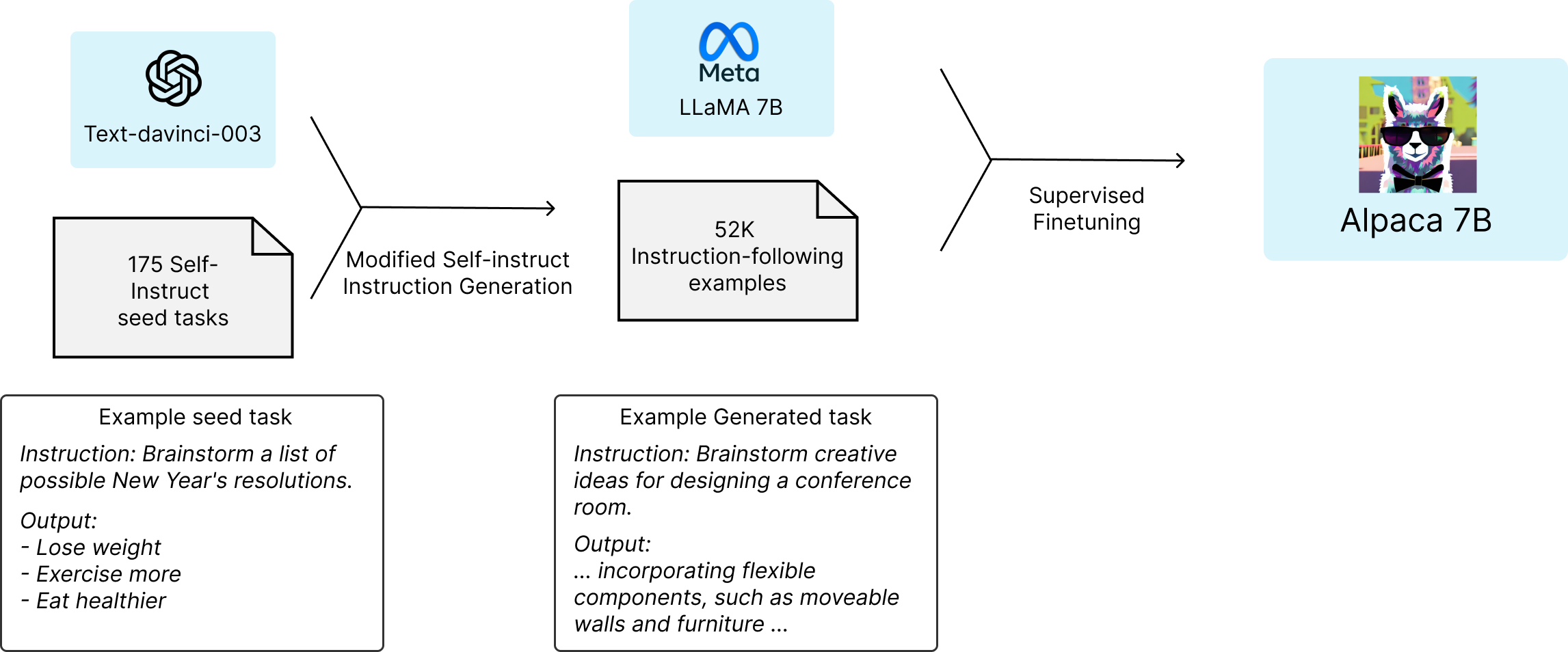
Although ChatGPT can be applied for almost every nlp task, many researchers have found that ChatGPT can’t beat the SOTA model of specific task like translation. However, LLMs can push the improvement of specific tasks.
references
- [1] Zero-Shot Information Extraction via Chatting with ChatGPT
- [2] ChatAug: Leveraging ChatGPT for Text Data Augmentation–2023
- [3] SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions–2022
- [4] Alpaca: A Strong, Replicable Instruction-Following Model